- Features by Edition
- Latest Features
- Licensing/Activation
- Installation
- Getting Started
- Data Sources
- Deployment/Publishing
- Server Topics
- Integration Topics
- Scaling/Performance
- Reference
- Guide to Views
- Keyboard Shortcuts
- Dates & Times
- Manage Fields
- Tokenised Data
- Using Formulae
- Scripting
- Mapping & GIS
- Advertising Options
- Legacy User Guide
- Translation Guide
- Specifications
- Video Tutorials and Reference
- Featured Videos
- Demos and screenshots
- Online Error Report
- Support
- Legal-Small Print
- Why Omniscope?
|
|
|
|||||
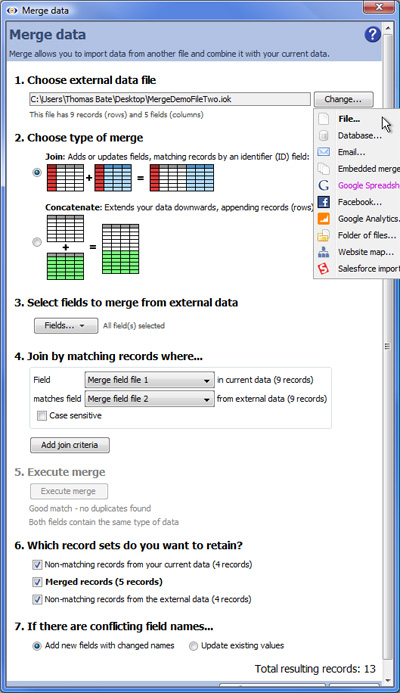
Merge Data (2.5)Using the Merge Data Wizard (2.5)Performing merges: Joins and Appends/ConcatenationsTo merge data from another file into your own Omniscope file, you must have at least one column in your data matching one of the columns in the external merge file(s). For example, to use a data file such as our By Countries merge files, you must have at least one column in your data that has the names of countries, or their ISO codes, or other standard identifiers. Note: Sample IOK merge files containing decimal geographic coordinates for countries and major cities, plus examples of other useful reference data available to merge into your data files are available here. Using the Merge Data WizardTo open the Merge Data wizard, click Main Toolbar: Data > Merge and the Merge Data wizard will appear:
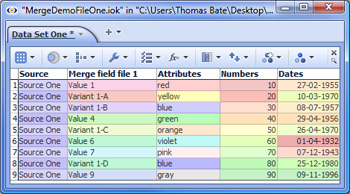
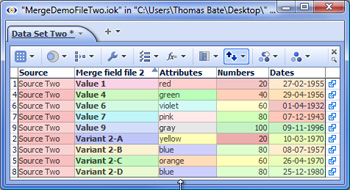
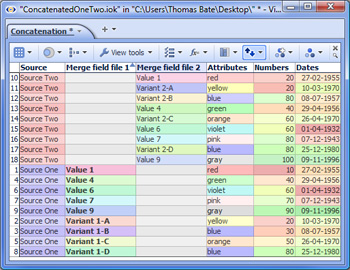
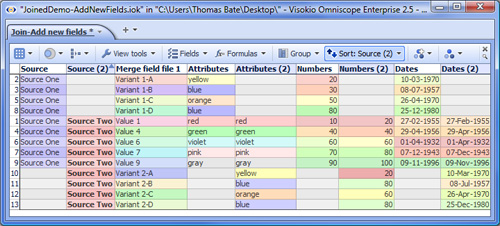
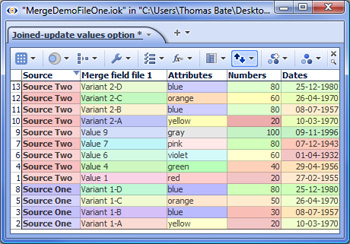
Note: If you use Date and Time fields as Join criteria, the names of the fields (columns) can be different but be sure that the format of the data in both fields is exactly the same. SUGGESTION: Before using a field (column) as a join criteria or matching field, it is good practise to check whether the values in the matching fields in both your starting file and the incoming merge file are unique (using Table View: View Tools > Tools > Select duplicate records). If both columns are unique, for a Join the number of merged records will be the same as the number of matching records, plus any non-matching records if you choose to keep them. If your starting file's matching field has duplicate records (such as multiple addresses with the same post code), Omniscope will warn you that permutations (additional records) will be created in the resulting merged file so that all address records receive their map coordinates. If you attempt to merge two files, both of which have duplicate values in the matching fields, try to specify as many additional join criteria as you can so as to minimise the number of permutations created. 7. If there are conflicting field names...- duplicate column names are normal for Concatenations, but before accepting the results of a Join, you must choose how to treat duplicate column names, i.e fields with exactly the same name in both files. There are two options: Add new fields with changed names - in the event of duplicate column names, Omniscope will notify you that new columns are being added and modify the names of duplicated columns by adding a (2). See example below. Update existing values - if you choose this options all values in columns of the starting file will be overwritten by the values in the incoming file if the column names are exactly the same. If you choose this option, ensure that the data in the incoming file always supersedes the data in the starting file. See example below: To finalise the merge, Click OK, Apply Merge to modify your file by adding in the corresponding column values from the Merge File. WARNING: Before starting to merge, it is good practise to protect your source files from accidental overwriting by saving then with the 'Warn on save' options ticked. If you click File > Save (or Ctrl+S) after merging, your original data file will be overwritten with the merged file. If you want to preserve your original data file (recommended) be sure to use File > Save As to save the merged file as a new file with a different name. Example Data Files:Demo files used in this section are available for download here:
Concatenation
Join adding new fields with changed names
Join updating the shared values in the current file with values in the incoming file
|